조회 성능 개선하면서 커버링 인덱스를 적용하여 조회 성능을 향상한 내용입니다.
현재 프로젝트에서 게시글 조회기능의 쿼리는 다음과 같습니다.
select b1_0.id,
b1_0.content,
b1_0.created_at,
b1_0.created_date,
b1_0.deleted,
b1_0.highest_temperature,
b1_0.like_count,
b1_0.lowest_temperature,
b1_0.member_id,
b1_0.open,
b1_0.place,
b1_0.ranking,
b1_0.road_condition,
b1_0.updated_at,
b1_0.version,
b1_0.weather
from board b1_0
where b1_0.weather = 'CLOUDY'
and b1_0.road_condition = 'SNOW'
and b1_0.place = 'PARTY'
and b1_0.open = true
and b1_0.lowest_temperature >= -7
and b1_0.highest_temperature <= 2
limit 0,10;
테이블의 인덱스를 다음과 같이 생성하였습니다.
- idx_created_date_ranking: weather, road_condition, place, open, lowest_temperature, highest_temperature
실행계획은 다음과 같습니다.

Using idex condition을 통해 스토리지 엔진에서 Mysql엔진으로 최대한 불필요한 레코드를 걸러낸 데이터를 가져오게 됩니다.
Limit절을 수행할 때 Limit은 Select 보다 뒤에 실행되지 때문에 Select에서 인덱스의 포함돼있지 않는 컬럼까지 조회를 위해 데이터 블록에 접근을 하게 되어 성능 저하가 발생하게 됩니다.
커버링 인덱스 적용
Select를 제외한 나머지 부분을 서브쿼리로 만들어 커버링 인덱스를 적용할 수 있게 수정해 보겠습니다.
select b1_0.id,
b1_0.content,
b1_0.created_at,
b1_0.created_date,
b1_0.deleted,
b1_0.highest_temperature,
b1_0.like_count,
b1_0.lowest_temperature,
b1_0.member_id,
b1_0.open,
b1_0.place,
b1_0.ranking,
b1_0.road_condition,
b1_0.updated_at,
b1_0.version,
b1_0.weather
from board b1_0
join (select id
from board
where board.weather = 'CLOUDY'
and board.road_condition = 'SNOW'
and board.place = 'PARTY'
and board.open = true
and board.lowest_temperature >= -7
and board.highest_temperature <= 2
limit 0,10) as temp on temp.id = b1_0.id;
실행계획을 확인하면 다음과 같습니다.

Extra 항목에서 Using index condition이 Using index로 변경되었습니다. 여기서 Using index는 커버링 인덱스를 사용한 것을 의미합니다.
인덱스를 사용하여 필요한 데이터의 id를 찾고, Limit의 개수만큼만 Select 절에 필요한 데이터 블록에 접근하여 불필요한 접근을 줄였습니다.
QueryDSL-JPA에서 적용
QueryDSL-JPA에서는 from 절에 서브쿼리를 적용할 수 없습니다.
따라서, 쿼리를 두 개로 나눠서 진행해야 합니다.
public Page<Board> findAllByCondition(SearchBoardRequest searchBoardRequest, Pageable pageable) {
BooleanBuilder conditionsBuilder = new BooleanBuilder();
conditionsBuilder.and(weatherCondition(searchBoardRequest));
conditionsBuilder.and(roadConditionCondition(searchBoardRequest));
conditionsBuilder.and(placeCondition(searchBoardRequest));
conditionsBuilder.and(QBoard.board.open.isTrue());
conditionsBuilder.and(lowestTemperatureConditions(searchBoardRequest));
conditionsBuilder.and(highestTemperatureConditions(searchBoardRequest));
// 1-커버링 인덱스로 필요한 데이터들의 Id를 조회
List<Long> ids = jpaQueryFactory
.select(QBoard.board.id)
.from(QBoard.board)
.where(conditionsBuilder)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
// 2-위의 결과로 얻은 Id로 필요한 데이터의 나머지 컬럼 조회
List<Board> content = jpaQueryFactory
.select(QBoard.board)
.from(QBoard.board)
.where(QBoard.board.id.in(ids))
.fetch();
JPAQuery<Long> countQuery = jpaQueryFactory
.select(QBoard.board.count())
.from(QBoard.board)
.where(conditionsBuilder);
return PageableExecutionUtils.getPage(content, pageable, countQuery::fetchOne);
}
- 커버링 인덱스를 활용하여 필요한 데이터의 Id만 조회합니다.
- 조회한 아이디를 사용하여 필요한 데이터의 나머지 컬럼을 조회합니다.
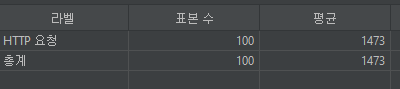
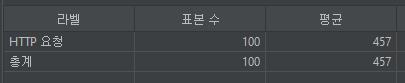
결과적으로 커버링 인덱스를 적용하여 성능을 1.5초에서 0.5초로 향상되었습니다.
- 적용 전
- 적용 후
'DB' 카테고리의 다른 글
| NCP를 활용한 데이터베이스(MySQL) Replication 구성 (0) | 2023.06.30 |
|---|---|
| 데이터베이스 클러스터링과 리플리케이션 (0) | 2023.06.25 |

